
ИТ База знаний
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP – адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP – АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Окружение, развёртывание, запуск Logstash в контейнере
Для развёртывания используем docker-compose, описанные здесь эксперименты проводились на MacOS и Ubuntu 18.0.4.
Образ logstash, который был прописан у нас в исходном docker-compose.yml, это docker.elastic.co/logstash/logstash:6.3.2
Его мы будем использовать для экспериментов.
Для запуска logstash мы написали отдельный docker-compose.yml. Можно конечно было из командной строки образ запускать, но мы ведь конкретную задачу решали, где у нас всё из docker-compose запускается.
- На каждой виртуалке стоит Filebeat, у которого в конфиге написано за какими лог файлами ему следить. Как только он детектит изменения – сразу построчно отправляет это в Logstash.
- Logstash получает себе в input строку, которую ему отправил Filebeat. Прогоняет его через все фильтра, определяет что с ним делать и отправляет в нужный output, в нужный индекс Еластика.
- Еластик получает лог, индексирует его, делая доступным для поиска, и цепляет поле timestamp – получается time-series табличка.
- Дев заходит на Кибану, вводит в строке поиска что ему там нужно найти, и находит. Или не находит.
> Кстати, цеплять рендомный timestamp – это плохо, так как теряется правильная последовательность логов.
Введение в ELK: собираем, фильтруем и анализируем большие данные

Внимание! Статье уже четыре года и многое в используемых технологиях могло измениться. Не забываем консультироваться с офф. документацией.
Что, если я скажу вам, что логи могут быть не только полезными и содержать тонну важной информации, но и что работа с ними может быть классной, интересной и увлекательной? Настолько же увлекательной, интересной и классной, как кликанье через удобный интерфейс в браузере, позволяющий в считанные секунды вывести любой график и сравнить его с другим графиком? Да чего там: что, если я скажу вам, что после прочтения этой статьи вы сможете развернуть полноценный аналог Google Analytics для ваших логов? А я это и скажу. Точнее, я это уже сказал. Погнали!
Подготовим vagrant-коробку
Прежде чем перейдём к самой сути, нам необходимо провести небольшую подготовительную работу. Возможно, вы уже использовали Vagrant. Если нет – обязательно узнайте что это такое и начните использовать. Знание Vagrant не нужно для этой статьи, но будет классно (и позволит избежать возможных несоответствий в результате), если вы будете запускать примеры кода ниже используя такой же как у меня конфиг vagrant-бокса.
Итак, создаём новую папку, выполняем в ней vagrant init , открываем Vagrantfile и помещаем туда этот конфиг:
Затем выполняем vagrant up и, пока наша виртуальная машинка создаётся, настраивается и запускается, читаем дальше.
ELK stack
ELK расшифровывается как elasticsearch, logstash и kibana. Раньше это были три самостоятельных продукта, но в какой-то момент они стали принадлежать одной компании и развиваться в одном направлении. Каждый из этих инструментов (с небольшими оговорками ниже) является полноценным независимым open source продуктом, а все вместе они составляют мощное решение для широкого спектра задач сбора, хранения и анализа данных. Теперь по порядку о каждом из них.
logstash
logstash – это утилита для сборки, фильтрации и последующего перенаправления в конечное хранилище данных. Вы могли слышать о fluentd – logstash решает ту же самую задачу, но написан на jruby и чуть более лучше дружит с elasticsearch (потому что теперь это продукт одной и той же компании, помните?).
Типичная конфигурация logstash представляет из себя несколько входящих потоков информации (input), несколько фильтров для этой информации (filter) и несколько исходящих потоков (output). Выглядит это как один конфигурационный файл, который в простейшем варианте (который не делает вообще ничего) выглядит вот так:
Не волнуйтесь, мы скоро перейдём к настоящим примерам.
– Так, так, стоп, Кирилл. Чё ещё за входящие потоки, какие ещё фильтры? Может пример какой приведёшь для этих терминов?
Привожу: допустим, у вас есть лог веб-сервера (nginx). Это входящий поток информации, input. Допустим, вы хотите каждую запись лога не только превратить в json-объект, но ещё и добавить гео-информацию о ней, основываясь на ip. Это фильтр, filter. А после того, как запись лога обработана и обогащена гео-данными, вы хотите отправить её в elasticsearch (скоро поймём почему). Это исходящий поток информации, output.
При этом у вас может быть сколько захочется input’ов, сколько приспичит фильтров (но не забудьте, что чем больше фильтров, тем больше ресурсов понадобится на обработку каждой записи) и сколько душе угодно output’ов. Logstash предоставляет из коробки внушительный набор готовых решений, поэтому вам не придётся писать свой фильтр для гео-данных, например. Он уже есть из коробки. Это, кстати, выгодно отличает logstash от fluentd.
elasticsearch
Изначально, elasticsearch – это решение для полнотекстового поиска, построенное поверх Apache Lucene, но с дополнительными удобствами, типа лёгкого масштабирования, репликации и прочих радостей, которые сделали elasticsearch очень удобным и хорошим решением для высоконагруженных проектов с большими объёмами данных.
Особенно доставляет в elasticsearch его простота и работоспособность из коробки. Конфигурация по-умолчанию скорее всего будет работать как надо для проектов средней и относительно высокой нагруженности. При этом вокруг ES сложилось отличное сообщество, которое всегда подскажет, как правильно настроить ваш ES-кластер для вашей конкретной задачи.
В какой-то момент elasticsearch стал настолько хорош, что использовать его только для поиска по товарам в интернет-магазинах (ну или там поиску по Basecamp) стало глупо и множество компаний начали основывать на ES свои решения по централизованному хранению логов и различной аналитики.
kibana
И вот у нас есть logstash, который собирает и обрабатывает данные со всех ваших тысяч серверов и elasticsearch, который изо всех сил эти данные хранит и позволяет искать по ним. Чего не хватает? Верно, не хватает Angular.js.
Поэтому в какой-то момент товарищ Rashid Khan написал для elasticsearch красивое Angular.js приложение kibana, позволяющее братьискать данные по elasticsearch и строить множество красивых графиков. Ребята из elasticsearch не дураки, поэтому, увидев всё удобство этого решения, они забрали разработчика kibana к себе на борт.
Помните, я сказал, что все элементы ELK – независимые продукты? На самом деле, kibana бесполезна без elasticsearch. Это очень (очень) удобный интерфейс, позволяющий любому в вашей компании построить себе красивую панельку, на которую выводить аналитику всего, что logstash отправил в elasticsearch.
Пора практиковаться!
У меня возникла проблема: в какой-то момент в mkdev.me произошла какая-то беда, и чтобы разобраться в ней мне нужно было внимательно изучить что-то вроде сотни с лишним мегабайт логов. Удовольствие от использования grep для этой задачи сомнительное, поэтому я решил взять лог с сервера, залить его в elasticsearch при помощи logstash и спокойно проанализировать проблему через браузер при помощи kibana.
Внимание! Возможно, у вас нет пары сотен с лишним мегабайт логов production приложения и вы скажете “э! а мне то чего пихать в elasticsearch”? Честно – не знаю. Но я почти уверен, что у вас локально лежит какое нибудь Ruby on Rails приложение, над которым вы работаете. А значит в папке log этого приложения есть необходимый вам файлик. Вот его и возьмите. А если нет такого файла, то можете попробовать найти в интернете чужие логи.
Не отдам же я вам логи mkdev, в самом-то деле.
Заходим в виртуалку: vagrant ssh .
Установка logstash
Я использовал logstash 2.2.0, документация по его установке валяется на оф. сайте. Прежде чем перейти к установке необходимо дополнительно установить на машине java. Выполняем одно за другим:
Всё, готово. Установили.
Установка elasticsearch
Версия elasticsearch тоже 2.2.0
Установка kibana
Используемая версия Kibana: 4.4.2. В реальных условиях, конечно, kibana должна быть отделена от logstash и elasticsearch и крутиться на отдельном сервере.
Конфигурируем logstash
У нас будет всего один input – stdin, стандартный ввод. Он позволит нам загрузить все данные из нашего лог-файла стандартной программой cat . Обратите внимание на type – к каждой итоговой записи, попадающей в output будет добавлено это поле.
Самая сложная часть – фильтры. Я использую multiline, потому что каждая запись в логах rails занимает несколько строчек. Опция pattern указывает на начало каждой записи.
grok – это регулярные выражения на стероидах. Позволяет определять конкретные шаблоны регулярных выражений, которые могут содержать в себе другие шаблоны. В logstash куча встроенных шаблонов grok. К сожалению, для rails там встроенного шаблона нет. После недолгих поисков в интернете я нашёл почти готовый шаблон, немного отредактировал его и он отлично сработал для логов mkdev.me (см. чуть ниже).
Найдите в папке logstash-2.2.0 папку patterns , закиньте туда файл rails со следующим содержанием:

- mkdev
- Менторы
- Специализации
- Контент
- Стать ментором
- О проекте
- Для компаний
- Что такое менторство
- Как проходит обучение
- Цены
- FAQ
- Impressum
- Аккаунт
- Записаться
- Войти
- Соцсети





© Copyright 2014 — 2021 mkdev | Privacy Policy | Lang: Russian
What is Kibana?
Kibana is a data visualization which completes the ELK stack. This tool is used for visualizing the Elasticsearch documents and helps developers to have a quick insight into it. Kibana dashboard offers various interactive diagrams, geospatial data, and graphs to visualize complex quires.
It can be used for search, view, and interact with data stored in Elasticsearch directories. Kibana helps you to perform advanced data analysis and visualize your data in a variety of tables, charts, and maps.
In Kibana there are different methods for performing searches on your data.
Here are the most common search types:
| Search Type | Usage |
| Free text searches | It is used for searching a specific string |
| Field-level searches | It is used for searching for a string within a specific field |
| Logical statements | It is used to combine searches into a logical statement. |
| Proximity searches | It is used for searching terms within specific character proximity. |
Features of Kinbana:
- Powerful front-end dashboard which is capable of visualizing indexed information from the elastic cluster
- Enables real-time search of indexed information
- You can search, View, and interact with data stored in Elasticsearch
- Execute queries on data & visualize results in charts, tables, and maps
- Configurable dashboard to slice and dice logstash logs in elasticsearch
- Capable of providing historical data in the form of graphs, charts, etc.
- Real-time dashboards which is easily configurable
- Enables real-time search of indexed information
Advantages and Disadvantages of Kinbana
- Easy visualizing
- Fully integrated with Elasticsearch
- Visualization tool
- Offers real-time analysis, charting, summarization, and debugging capabilities
- Provides instinctive and user-friendly interface
- Allows sharing of snapshots of the logs searched through
- Permits saving the dashboard and managing multiple dashboards
Централизованный сбор Windows Event Logs с помощью ELK (Elasticsearch – Logstash – Kibana)
 Передо мной встала задача организовать сбор Windows Event Logs в некое единое хранилище с удобным поиском/фильтрацией/возможно даже визуализацией. После некоторого поиска в интернете я натолкнулся на чудесный стек технологий от Elasticsearch.org – связка ELK (Elasticsearch – Logstash – Kibana). Все продукты являются freeware и распространяются как в виде архива с программой, так и в виде пакетов deb и rpm.
Передо мной встала задача организовать сбор Windows Event Logs в некое единое хранилище с удобным поиском/фильтрацией/возможно даже визуализацией. После некоторого поиска в интернете я натолкнулся на чудесный стек технологий от Elasticsearch.org – связка ELK (Elasticsearch – Logstash – Kibana). Все продукты являются freeware и распространяются как в виде архива с программой, так и в виде пакетов deb и rpm.
Что такое ELK?
Elasticsearch
Elasticsearch – это поисковый сервер и хранилище документов основанное на Lucene, использующее RESTful интерфейс и JSON-схему для документов.
Logstash
Logstash – это утилита для управления событиями и логами. Имеет богатый функционал для их получения, парсинга и перенаправленияхранения.
Kibana
Kibana – это веб-приложение для визуализации и поиска логов и прочих данных имеющих отметку времени.
В данной статье я постараюсь описать некий HOW TO для установки одного сервера на базе Ubuntu Server 14.04, настройки на нем стека ELK, а так же настройки клиента nxlog для трансляции логов на сервер. Хочу однако отметить что данный стек технологий можно использовать гораздо шире. Какие логи вы будете пересылать, парсить, хранить и в последствии пользоваться поискомвизуализацией по ним зависит только от вашей фантазии. По использованию данных технологий есть множество вебинаров на сайте http://www.elasticsearch.org/videos/ .
Установка Ubuntu 14.04
Дабы не повторяться с установкой дистрибутива Ubuntu 14.04 приведу ссылку на статью моего коллеги по блогу, Алексея Максимова – Настройка прокси сервера Squid 3.3 на Ubuntu Server 14.04 LTS. Часть 1. Установка ОС на ВМ Hyper-V Gen2 . Все действия по настройке можно проделать аналогичные, за исключением установки минимального UI и настройки второго сетевого интерфейса – его можно исключить на стадии создания виртуальной машины, ведь сервер будет находиться внутри периметра вашей сети.
Установка JAVA 7
Так как два из трех используемых продуктов написаны на JAVA нам придется его установить. Устанавливать будем Oracle Java 7, так как Elasticsearch рекомендует устанавливать именно его.
Добавляем Oracle Java PPA в apt:
И устанавливаем последнюю стабильную версию Oracle Java 7:
Проверить версию Java можно набрав команду
Установка Elasticsearch
Хотя документация по Logstash рекомендует использовать Elasticsearch версии 1.1.1, он прекрасно работает и с последней стабильной версией 1.3.1. Именно ее мы и установим.
Добавляем публичный GPG ключ в apt:
Создаем source list apt:
И устанавливаем Elasticsearch 1.3.1:
Базовая конфигурация Elasticsearch очень простая, нам нужно указать в файле конфигурации всего два параметра – имя кластера и имя ноды.
Открываем elasticsearch.yml:
И раcкомментируем строки “cluster.name: elasticsearch” и “node.name: “Franz Kafka””. Вместо значений по умолчанию можно указать свои.
Создаем скрипты автозапуска elasticsearch:
Перед стартом сервера я рекомендую установить еще два плагина к elasticsearch – head и paramedic. Первый позволяет управлять сервером поиска и индексами документов, второй следит за “здоровьем” пациента, выводя графики с различной полезной информацией.
Плагины к elasticsearch устанавливаются с помощью команды plugin прямо из github:
Доступ к результатам работы плагинов можно получить через url вида http://elasticsearch.server.name:9200/_plugin/head/ или http://elasticsearch.server.name:9200/_plugin/paramedic/
После чего можно запускать сам сервер:
Установка Kibana
Так как Kibana это веб-приложение, перед его установкой нужно установить веб-сервер. Я воспользовался простейшим nginx.
Создаем папку www для будущего приложения:
Даем nginx права на папку:
Скачиваем последний архив с файлами Kibana (на настоящий момент это kibana-3.1.0.tar.gz):
И копируем его содержимое в папку /var/www:
Скачиваем файл конфигурации для работы Kibana под nginx:
Открываем его в редакторе nano и указываем в какой папке лежат файлы Kibana:
Заменяем строку
root /usr/share/kibana3;
на строку
root /var/www;
Копируем данный файл как файл по умолчанию для nginx:
И перезапускаем nginx:
Теперь если перейти по адресу http://elasticsearch.server.name/ мы увидим стартовый дашборд Kibana. Если вы не планируете создавать других дашбордов, то можно сразу поставить по умолчанию дашборд Logstash.
Для этого нужно заменить файл дашборда по умолчанию на файл дашборда Logstash:
Основные настройки Kibana находятся в файле config.js по адресу /var/www/config.js, однако “из коробки” все работает замечательно.
Установка Logstash
Добавляем source list Logstash в apt:
И устанавливаем Logstash:
Logstash установлен, однако конфигурации у него нет. Конфигурационный файл Logstash состоит из 3х частей – input, filter и output. В первой определяется источник событий или логов, во второй с ними производятся необходимые манипуляции, и в третей части описывается куда обработанные данные нужно подавать. Подробно все части описаны в документации http://logstash.net/docs/1.4.2/ и есть некоторые примеры.
Для текущей задачи, мною была написана следующая простая конфигурация:
Создадим файл в папке конфигураций Logstash
И поместим туда следующую конфигурацию
Разберем по порядку:
В разделе input
tcp <> – открывает tcp порт и слушает его
type => “eventlog” говорит Logstash что на входе будут данные типа eventlog (известный формат полей для Logstash)
port => 3515 – номер потра
format => ‘json’ – говорит Logstash о том, что данные придут “обернутые” в JSON
Никаких манипуляций с логами я не совершаю, потому раздел filter у меня пустой. Хотя если Вам будет необходимо, к примеру, привести дату к нужному формату, или убрать из лога одно или несколько полей, то в данном разделе можно эти манипуляции описать.
В разделе output
elasticsearch <> – оправляет данные в elasticsearch
cluster => “elasticsearch” – указывает на имя кластера, что мы указывали при конфигурировании Elasticsearch
node_name => “Franz Kafka” – указывает на имя ноды.
Сохраняем файл и запускаем Logstash
Можно проверить что порт tcp 3515 слушается командой:
Установка nxlog
Идем на сайт nxlog ( http://nxlog.org/download) и скачиваем саму свежую версию для Windows.
Устанавливаем на нужной Windows машине данный клиент. Настройки он хранит в файле nxlog.conf по адресу по умолчанию “c:Program Files (x86)nxlogconf” (для 32-битной версии “c:Program Filesnxlogconf”).
Для решения данной задачи я написал конфигурационный файл следующего содержания:
У nxlog конфигурационный файл так же состоит из нескольких частей – это Extension, Input, Output и Route. Об устройстве конфигурационного файла nxlog можно почитать в документации к nxlog ( http://nxlog.org/nxlog-docs/en/nxlog-reference-manual.html) .
Могу отметить следующие детали – в разделе Input используется модуль im_msvistalog (для операционных систем Vista/2008 +) для более старых ОС нужно раскомментировать строку с указанием на модуль im_mseventlog. Модуль im_msvistalog позволяет фильтровать логи через XPath запрос (подробнее тут – http://msdn.microsoft.com/en-us/library/aa385231.aspx) . В приведенном конфигурационном файле выбираются логи из трех источников – это журналы Application, Security и System, причем из Application и System выбираются только Critical, Error и Warning логи, для Security выбираются все логи, так как они там другого типа – Info. Команда Exec to_json; “оборачивает” данные в JSON формат.
В разделе Output указывается модуль om_tcp для отправки данных по протоколу tcp, указывается хост и порт подключения.
Раздел Route служит для указания порядка выполнения действий, так как клиент nxlog умеет читать из множества источников и отсылать во множество приемников. Все это можно подчерпнуть из документации к продукту.
Настроив конфигурационный файл не забудьте его сохранить и можно запускать клиент через оснастку Службы (Services) или через командную строку:
Использование
Открыв в браузере Kibana (и перейдя на дашборд Logstash, если он у Вас не по умолчанию) мы увидим после всего проделанного следующую картину.
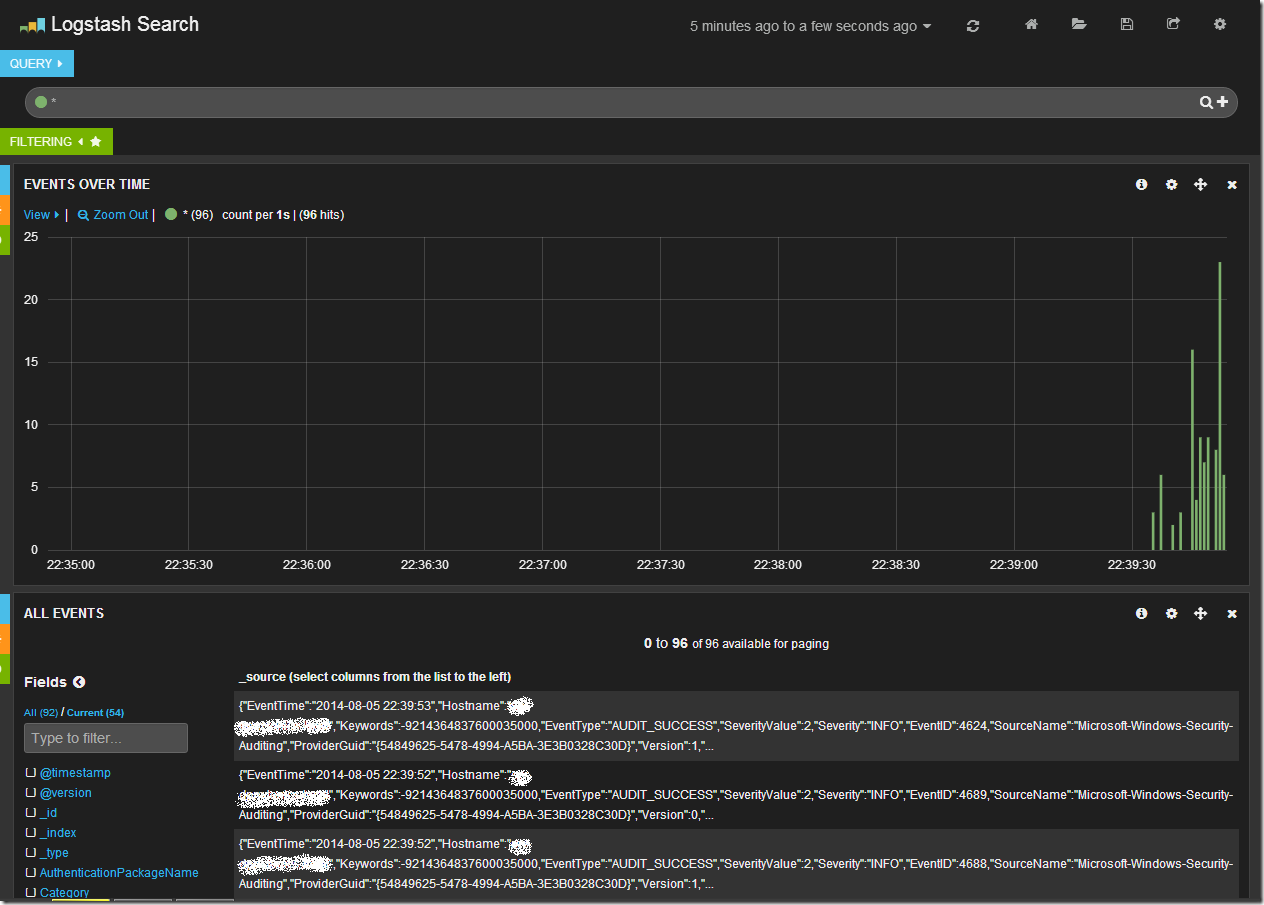
Центральный график на дашборде отражает количество записей в единицу времени. Сверху находится строка запроса и панель управления дашбордом. В нижней части таблица с данными.
Обратив свое внимание на таблицу данных мы увидим что данные показаны в “сыром” виде, однако слева от таблицы есть список полей. Щелкнув последовательно по чекбоксам с полями EventID, EventTime, EventType, Hostname, Sevirity, Message, Channel, мы получим уже более читабельный вид таблицы:
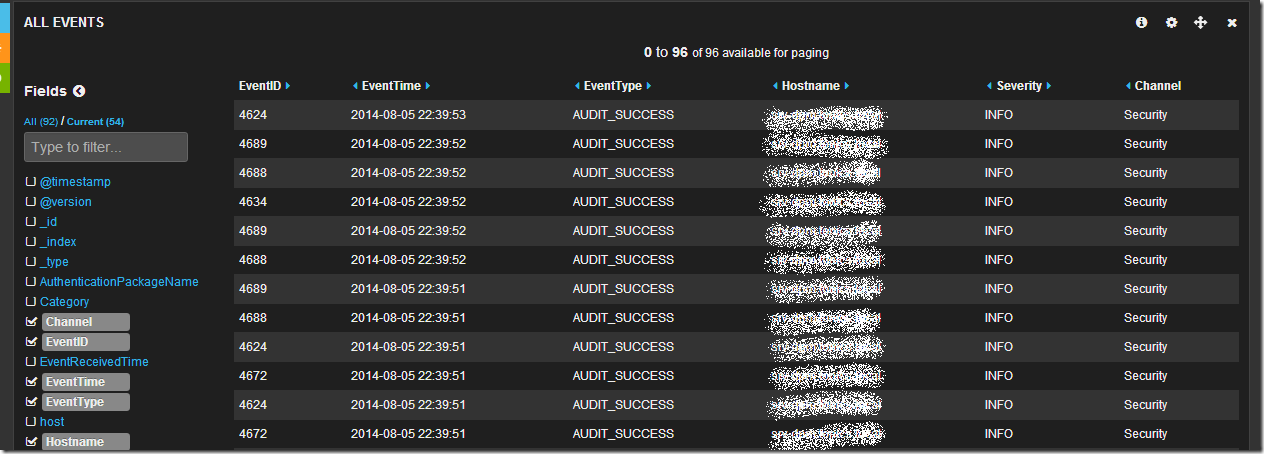
Просмотрев логи я вижу что в основном это логи из раздела Security, хочется понять какие приложения создают данные записи. Изучив список полей я нахожу поле ProcessName, если по нему кликнуть мышкой, то откроется интересное меню микроанализа по полю в котором будет перечислен TOP10 по количеству записей от процесса с их именами.
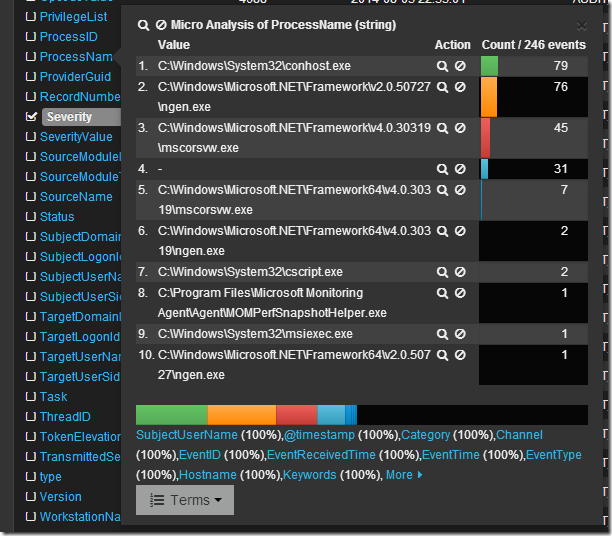
Если кликнуть по символу лупы рядом с именем процесса, то создастся фильтр по этому имени.
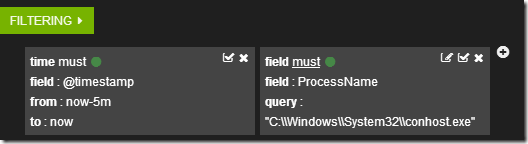
А данные в таблице отобразятся в соответствии с фильтрами.
Кликнув в таблице по любой записи можно развернуть ее в детальный вид, где будет видно все поля записи. Например так:
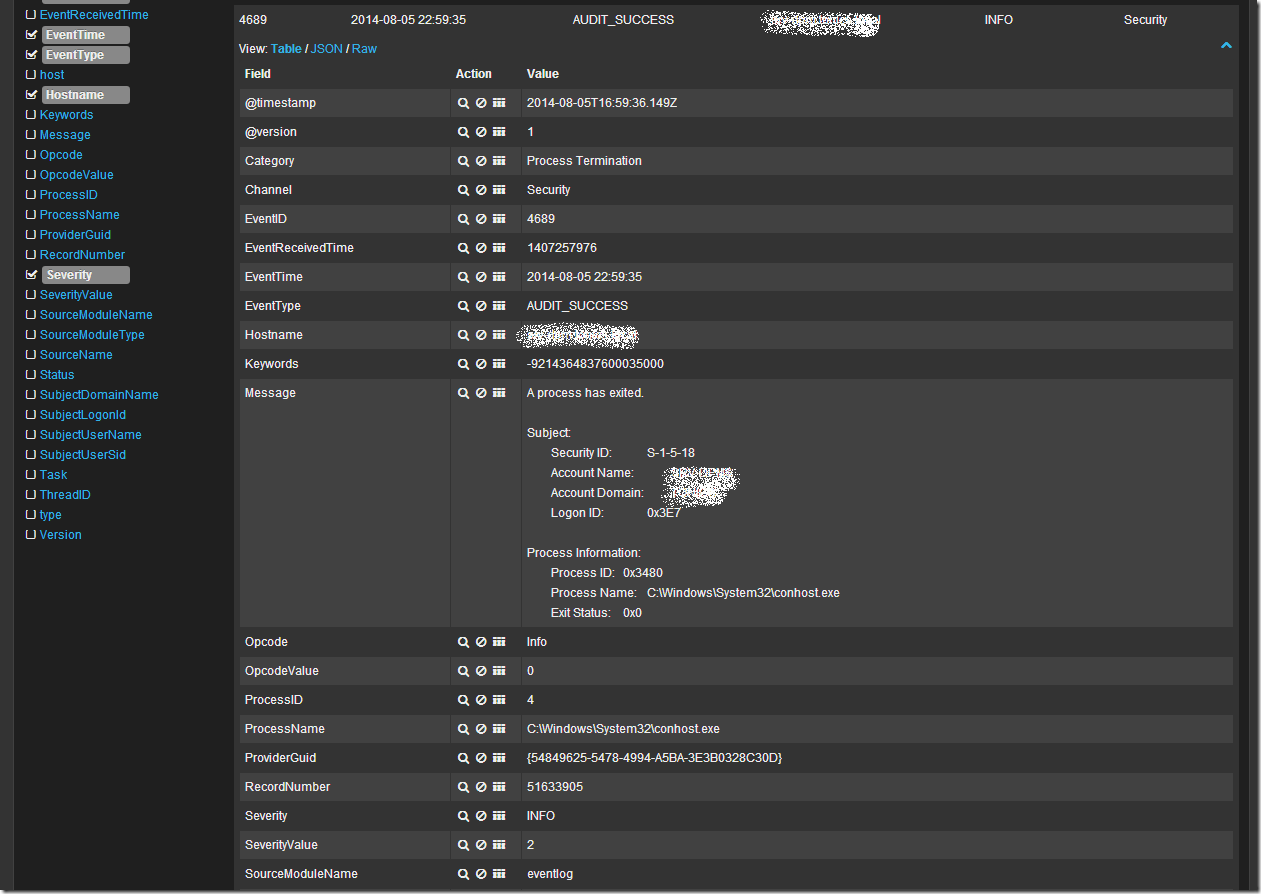
Ну и наконец если я просто хочу поискать по всем полям словосочетание “System Center” в поле запроса я пишу “System Center”. В случае поиска по конкретному полю можно воспользоваться конструкцией FieldName:”SearchQuery”, например ProcessName:”System Center”. Что бы исключить из выборки данные найденные с помощью конструкции можно воспользоваться оператором “-“, например -ProcessName:”System Center” или -“System Center”. Так же работают операторы OR и AND.
Более подробно о возможностях Kibana + Logstash + Elasticsearch можно узнать из документации и вебинаров на сайте elasticsearch.org. Здесь я показал лишь малую толику того что может эта замечательная связка инструментов.
При подготовке статьи я пользовался следующими источниками:

